
Un grupo de investigadores del Instituto Tecnológico de Massachussets (MIT) ha desarrollado un nuevo método, denominado operador de crecimiento lineal aprendido (LiGO), que aprende a hacer más grande un modelo de aprendizaje automático a partir de un modelo más pequeño, codificando el conocimiento que el modelo más pequeño ya ha adquirido. Esto permite un entrenamiento más rápido del modelo más grande.

Su técnica ahorra alrededor del 50% del costo computacional requerido para entrenar un modelo grande, en comparación con los métodos que entrenan un nuevo modelo desde cero. Además, los modelos entrenados con el método MIT funcionaron igual o mejor que los modelos entrenados con otras técnicas que también usan modelos más pequeños para permitir un entrenamiento más rápido de modelos más grandes.
Los modelos de lenguaje grandes como GPT-3, que es el núcleo de ChatGPT, se construyen utilizando una arquitectura de red neuronal llamada transformador. Una red neuronal, basada libremente en el cerebro humano, se compone de capas de nodos interconectados o ‘neuronas’. Cada neurona contiene parámetros, que son variables aprendidas durante el proceso de entrenamiento que la neurona utiliza para procesar datos.
Las arquitecturas de transformadores son únicas porque, a medida que estos tipos de modelos de redes neuronales crecen, logran resultados mucho mejores. Estos modelos suelen tener cientos de millones o miles de millones de parámetros que se pueden aprender.
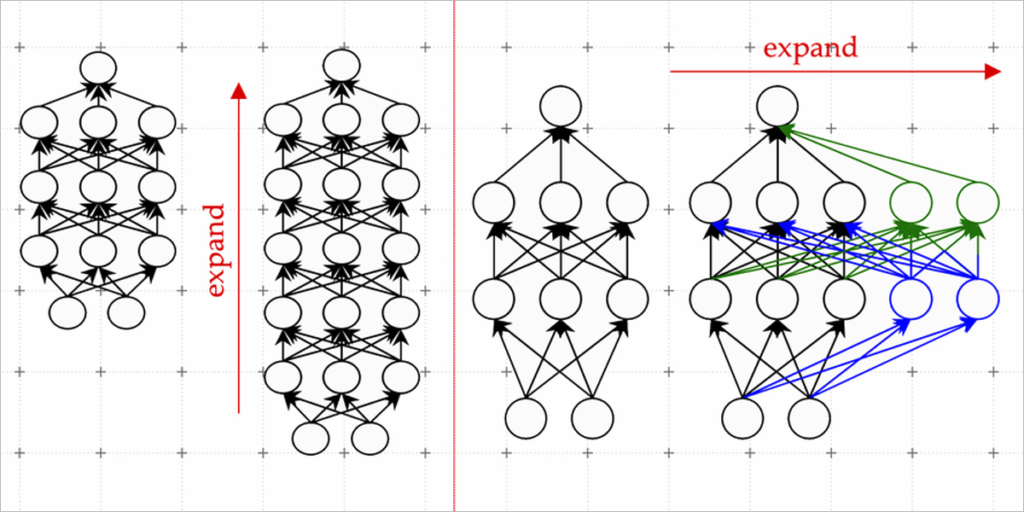
Una técnica eficaz se conoce como modelo de crecimiento. Usando el método de crecimiento del modelo, los investigadores pueden aumentar el tamaño de un transformador copiando neuronas, o incluso capas enteras de una versión anterior de la red, y luego apilándolas encima. Pueden ampliar una red agregando nuevas neuronas a una capa o hacerla más profunda agregando capas adicionales de neuronas.
Mapeo lineal de parámetros
Los investigadores del MIT utilizan el aprendizaje automático para aprender un mapeo lineal de los parámetros del modelo más pequeño. Este mapa lineal es una operación matemática que transforma un conjunto de valores de entrada, en este caso los parámetros del modelo más pequeño, en un conjunto de valores de salida, en este caso los parámetros del modelo más grande.
Su método, al que llaman operador de crecimiento lineal aprendido (LiGO), aprende a expandir el ancho y la profundidad de una red más grande a partir de los parámetros de una red más pequeña de una manera basada en datos.
Pero el modelo más pequeño en realidad puede ser bastante grande, tal vez tenga 100 millones de parámetros, y los investigadores podrían querer hacer un modelo con 1.000 millones de parámetros. Entonces, la técnica LiGO divide el mapa lineal en partes más pequeñas que un algoritmo de aprendizaje automático puede manejar.
LiGO también expande el ancho y la profundidad simultáneamente, lo que lo hace más eficiente que otros métodos. Un usuario puede ajustar cómo de ancho y profundo quiere que sea el modelo más grande cuando ingresa el modelo más pequeño y sus parámetros.
Cuando compararon su técnica con el proceso de entrenar un nuevo modelo desde cero, así como con los métodos de crecimiento del modelo, fue más rápido que todas las líneas de base. Los investigadores también descubrieron que podían usar LiGO para acelerar el entrenamiento de transformadores incluso cuando no tenían acceso a un modelo preentrenado más pequeño.