Un grupo de investigadores del Instituto Tecnológico de Massachussets (MIT) ha desarrollado una técnica de inteligencia artificial que aprende a representar datos de una manera que captura conceptos que se comparten entre las modalidades visuales y de audio. Usando este conocimiento, el modelo de aprendizaje automático puede identificar dónde se lleva a cabo una determinada acción en un vídeo y etiquetarla.
Los investigadores centran su trabajo en el aprendizaje de representación, que es una forma de aprendizaje automático que busca transformar los datos de entrada para facilitar la realización de una tarea como la clasificación o la predicción.
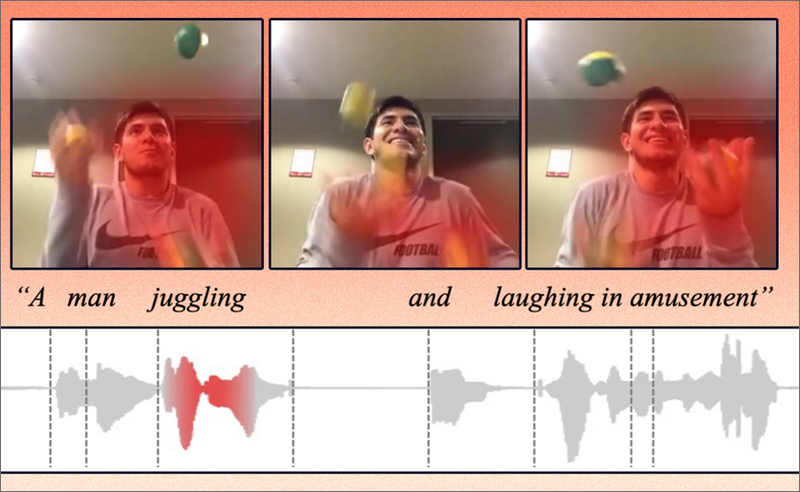
El modelo de aprendizaje de representación toma datos sin procesar, como vídeos y sus leyendas de texto correspondientes, y los codifica extrayendo características u observaciones sobre objetos y acciones en el vídeo. Luego mapea esos puntos de datos en una cuadrícula, conocida como espacio de incrustación. Cada uno de estos puntos de datos, o vectores, está representado por una palabra individual, por ejemplo, un clip de vídeo de una persona haciendo malabares podría asignarse a un vector etiquetado como ‘malabares’.
En lugar de codificar datos de diferentes modalidades en cuadrículas separadas, su método emplea un espacio de incrustación compartido donde dos modalidades se pueden codificar juntas. Esto permite que el modelo aprenda la relación entre las representaciones a partir de dos modalidades, como un vídeo que muestra a una persona haciendo malabares y una grabación de audio de alguien que dice ‘haciendo malabares’. Para ello, diseñaron un algoritmo que guía a la máquina para codificar conceptos similares en el mismo vector.
Máximo de 1.000 palabras para etiquetar
Los investigadores restringen el modelo para que solo pueda usar 1.000 palabras para etiquetar vectores, aunque éste puede decidir qué acciones o conceptos quiere codificar en un solo vector. El modelo elige las palabras que cree que representan mejor los datos. Así, un usuario puede ver más fácilmente qué palabras usó la máquina para concluir que el vídeo y las palabras habladas son similares.
Probaron el modelo en tareas de recuperación multimodal utilizando tres conjuntos de datos: un conjunto de datos de vídeo, texto con clips de vídeo y subtítulos de texto; un conjunto de datos de vídeo, audio con clips de vídeo y subtítulos de audio hablados; y un conjunto de datos de imagen, audio con imágenes y subtítulos de audio hablados.
Para probar este modelo, los investigadores proporcionaron un conjunto de datos de audio y vídeo, para los que el modelo eligió 1.000 palabras para representar las acciones en los vídeos. Posteriormente, los investigadores enviaron consultas de audio y el modelo trató de encontrar el clip que mejor coincidía con esas palabras habladas.